
In distributed systems, frequently encountered technical terms usually include multiple copies, data partitions, consensus algorithms, transactions, etc. These technologies are very important in the design of distributed systems. Discuss the reliability, scalability and maintainability of the system, describe the problems that these technologies solve, and hope to help everyone.
reliability
If the system can work normally when any abnormality occurs, the system is completely reliable. In fact, there are many types of exceptions, and some exceptions are usually difficult to avoid. Therefore, it is very important to understand the possible abnormalities and analyze how to recover quickly when they occur. Generally, abnormalities include hardware abnormalities, software abnormalities and human abnormalities.
Hardware exception
There are many types of hardware abnormalities, and damage to any components such as the hard disk and power supply may cause the server to fail to work normally. Usually avoid typical exceptions. However, some technical means can achieve rapid recovery after an abnormality occurs. Whether from a software perspective or a hardware perspective, the basic solutions are redundant.
From a hardware point of view, we can use single-machine redundancy for multiple hardware. When some hardware is abnormal, we can quickly replace the faulty hardware with good hardware. This kind of hardware redundancy is very important for data center-level hardware. Failure is useless.
From a software point of view, we can achieve rapid recovery through multiple copies (replication). When the hardware of the server is abnormal, traffic can be imported to the new copy at the software level (in fact, there is hardware redundancy, but this method is particularly flexible).
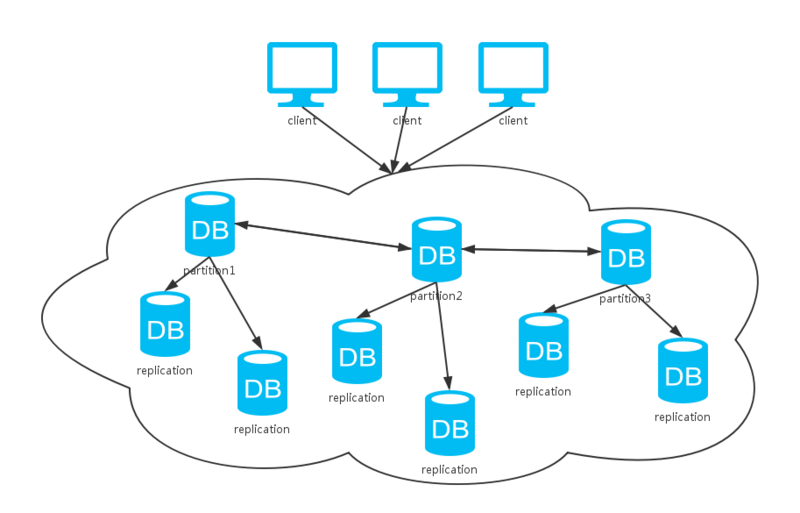
In addition to replication, sometimes in order to reduce the impact of a single server failure on all users, user data can be partitioned (partitioned). A single server only stores data for certain users, so a single server failure will only affect certain users. After specifying multiple copies (replication), how to ensure the data consistency of multiple copies becomes a problem again. Paxos and Raft algorithms are designed to solve such problems.
Software exception
Software exceptions usually also refer to system errors, which also include system errors written by yourself and errors in related service systems. Therefore, when a software exception occurs, a quick recovery method is also needed. There are usually three methods:
1. Avoid this problem by adjusting the existing configuration parameters of the software
2. Restart the software or related services to eliminate the abnormal state
3. Directly fix the error and upgrade the version
Artificial anomaly
The software itself and the server that runs the software are managed by people, but people make mistakes. Sometimes they execute wrong commands, causing the system to fail to operate normally. Fatal errors may delete data from a certain server. In this case, in order to recover quickly, the idea of multiple copies (Replication) is usually used to avoid problems.
Scalability
The workload of the system is usually not static. When the workload increases, you can usually increase machine resources to maintain performance. The number of machines that need to be added depends on the scalability of the system. The better the scalability of the system, the fewer machine resources need to be added.
The most perfect scalability is linear scalability, that is, when the workload is expanded to N times the original capacity, only N times the machine is required to maintain the same performance. The worst scalability is that there is no scalability, that is, when the workload is expanded to N times the original capacity, even if more computers are added, the performance cannot be maintained as before.
Expansion is usually two ways of thinking. One is vertical expansion, which means replacing existing machines with better machines, and the other is horizontal expansion, which means using more machines.
For vertical expansion, the advantage is that it has no impact on the business, but the disadvantage is that better machines are expensive. Usually, you get the price you want to pay, and one penny can only buy two cents. In fact, there is always an amount of data that a single computer cannot hold. At present, vertical expansion is naturally impossible.

For horizontal expansion, the cooperation of software scale is usually required. For a stateless system, usually only the system that needs to be expanded is deployed on the newly added computer; otherwise, it is usually expanded. For a stateful system, it usually refers to a storage system and usually allocates data partitions. In this way, the newly added computer can migrate data and corresponding workloads from the old computer through the migration partition. Advantage
Post time: Jan-21-2021